最先端のAIエージェント・プラットフォームと実績あるAIエージェント・ソリューションで、組織を変革し、自信を持ってAIエージェントを導入してください。
我々はベストから学んだ
Kore.aiは、最も困難な課題を抱える企業のお客様にサービスを提供することで、ビジネスを構築してきました。今日、Kore.aiは何百社もの企業に信頼され、AIを活用してビジネスを再構築しています。
エンタープライズAIソリューション
価値のあるところにAIを組み込むAIエージェントで、ビジネスを再構築しましょう。
AI for Work
インテリジェントな自動化と洞察により、企業知識の検索、ワークフローの自動化、生産性の向上を実現するAIエージェントが従業員を支援します。
AI for Service
あらゆるチャネルで24時間365日のサポートと人間のような対話を提供するAIエージェントで、カスタマー・エクスペリエンスに革命を。AIエージェントが案内することで、人間のエージェントを優位に立たせることができます。


KORE.AIスタック
あなたのビジネスのための単一のAIエコシステム
実験から実用的なAIエージェントまでの摩擦と混乱を減らす。
クリックしてエコシステムを探る
エンタープライズ・データ・ソース
- エンタープライズアプリ
- 非構造化データ
企業統合
- チャンネル
- コンタクトセンター
- ASR/TTS/AIモデル
- ツール/ダイアログ
- APIフック / SDK
- アシスタント・チャット
- クラウド/インフラ
画像にカーソルを合わせると詳細が表示されます。
エージェント・マーケットプレイス
業界別ソリューション250以上のエージェント&ツールテンプレート
銀行向けAIヘルスケア向けAIリテール向けAIIT向けAI人事向けAI採用AI
Kore.aiマーケットプレイスとインダストリーソリューションは、オープンでカスタマイズ可能なAIエージェントコレクションであり、企業や開発者がAIを活用したエージェント、ツール、構築済みテンプレートを迅速に導入できるようにします。
AI for Work
- カスタムAIエージェント
- エンタープライズサーチ
- ワーク・オーケストレーター
- AIエージェント人事、IT、採用
AI for Workは、部門を超えた従業員のために構築されています。繰り返しのワークフローを自動化し、RAGを使用してナレッジを検索し、オペレーションをオーケストレーションすることで、生産性を向上させるカスタムAIエージェントを作成することができます。これにより、従業員はハードワークではなく、よりスマートに働くためのツールを手に入れることができます。さらに詳しく
AI for Service
- カスタムAIエージェント
- AIコンタクトセンター
- エージェント・アシスト
- あらかじめ構築されたAIエージェント銀行、ヘルスケア、小売
AI for Serviceは、コンタクトセンターが人間のようなセルフサービスを提供し、ライブエージェントをインテリジェントに支援し、継続的な改善を推進するカスタマーサービスAIエージェントを構築することを可能にするソリューションです。あらゆる顧客対応が、よりパーソナライズされ、効率的で、スケーラブルになります。さらに詳しく
AI for Process
- トリガー、ワークフロー、AIエージェント
- 人間によるレビューと承認
- プロセス監視ツール
- プロセステンプレート
AI for Processにより、プロセス改善のプロフェッショナルは、複雑で機能横断的なバックエンドプロセスを自動化し、コンプライアンスを強化し、文脈に即した実用的な洞察を示すAIエージェントを構築することができます。これにより、一貫した結果、よりスマートな意思決定、企業の俊敏性が向上します。さらに詳しく
マルチエージェント・オーケストレーション
- マルチエージェントコラボレーション、スーパーバイザー、エージェントメモリー(長期・短期)、エージェントツール、完全自律への誘導、DialogGPT、エージェント間プロトコル(A2Aなど)
マルチエージェント・オーケストレーションは、AIエージェントに文脈に沿ったコラボレーション、メモリの共有、そして単純なタスクから完全にオーケストレーションされた意思決定まで、異なる自律性レベルで動作する能力を与えます。DialogGPTのようなフレームワークのサポートにより、複雑なワークフロー全体にわたってリッチなエンドツーエンドの推論を可能にします。さらに詳しく
AIエンジニアリング・ツール
- プロンプトスタジオ、評価スタジオ、モデルハブ、モデルファクトリー
Kore.aiエージェント・プラットフォームには、開発を加速させる3つのAIエンジニアリング・ツールがあります。Model Hubは、オープンソース、商用、または微調整されたモデルをプラットフォームに接続します。プロンプトスタジオは、モデル間でプロンプトをテストしたり、75以上のビルド済みプロンプトを使用することで、パフォーマンスを最適化します。また、Evaluation Studioは、エージェントのパフォーマンスを監視し、改善するためのリアルタイムの洞察を提供します。さらに詳しく
検索とデータAI(エージェント・コンテキスト)
- 100以上のコネクター、エージェント型RAG、ナレッジグラフ+マルチベクトル、ティーチャビリティ
当社の検索AIとデータAIプラットフォームレイヤーは、インテリジェンスと柔軟性を組み込んだ強力な情報検索を可能にします。100以上の検索コネクタとエージェント型RAGのネイティブサポートにより、企業データ全体から文脈に応じた回答を取得できます。さらに詳しく
観測可能性
- エージェント・トレース、インサイト、アナリティクス、モニタリング・イベント
Observabilityが組み込まれているため、チームはトレース、リアルタイムのAI分析、詳細な監査ログの監視イベント、実用的な洞察を通じて、エージェントのパフォーマンスを深く可視化できます。これにより、AIの動作が透明で、測定可能で、AIガバナンスポリシーに準拠していることが保証されます。さらに詳しく
ノーコード
プロコードツール
- ノーコード・ビルダー、SDK、プロコード・エクステンション、テンプレート、MCPインテグレーション
ノーコード、プロコードのビルダー機能により、チームはAIエージェントを迅速に構築し、大規模に管理することができます。ノーコードツールを使用して、直感的なインターフェイスでエージェント、ツール、ワークフローを設計します。AIエージェントのテンプレートとプロコード拡張機能により、より高度なカスタマイズが可能です。さらに詳しく
AI 安全、セキュリティ、コンプライアンス、ガバナンス
-
ガードレイル、RBAC、バージョン、監査ログ、エンタープライズグレードのセキュリティ、コンプライアンス





AIの安全性、コンプライアンス、ガバナンスにより、ポリシーを実施し、規制基準を満たし、責任あるAIの動作をスケールで保証するための企業向けガードレールを提供します。コンプライアンスフレームワークから堅牢なアクセス制御、倫理的なセーフガードまで、このプラットフォームは信頼と説明責任のために構築されています。詳細はこちら



























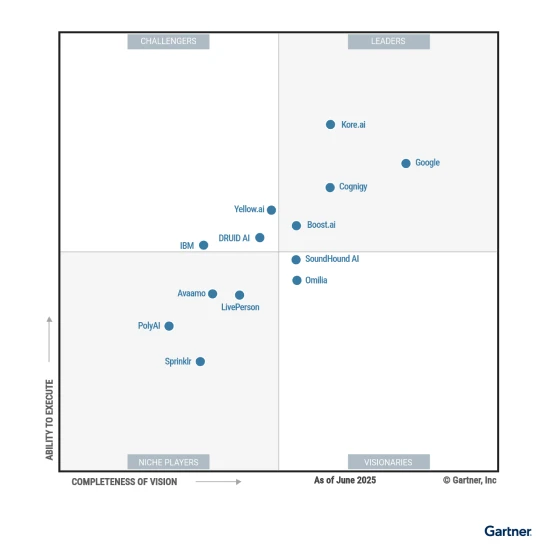
Kore.aiがGartner® Magic Quadrant™のリーダー
に選ばれました。
Gartner® Magic Quadrant™ for Conversational AI Platforms(会話AIプラットフォームに関するガートナー®マジック・クアドラント™)に、生成AIを活用する会話AIエージェントとツールが追加されました。本レポートは、複雑な自動 化やマルチモーダルインタラクションの ための会話型AIプラットフォームを選択するアプリケーションリーダーをガイドします。
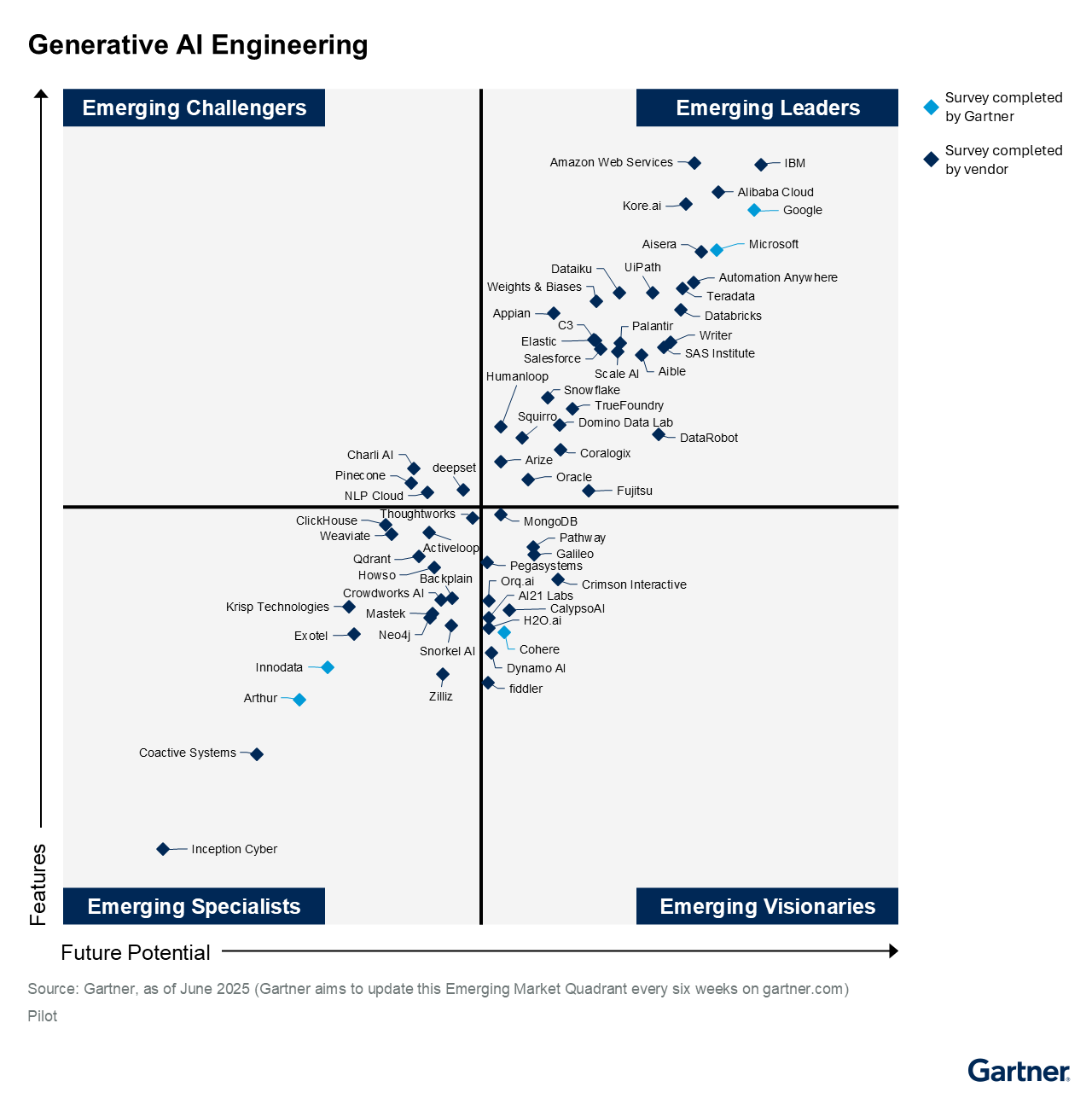
Gartner® Emerging Market QuadrantのGenAIエンジニアリング部門リーダー
Gartner eMQ for Generative AI Engineeringレポートは、データパイプライン、モデル管理、オーケストレーション、観測可能性、自動化など、複数のエージェント、企業規模のスタック、エンドツーエンドにわたる完全なエージェントアプリケーションのライフサイクルをカバーしている。
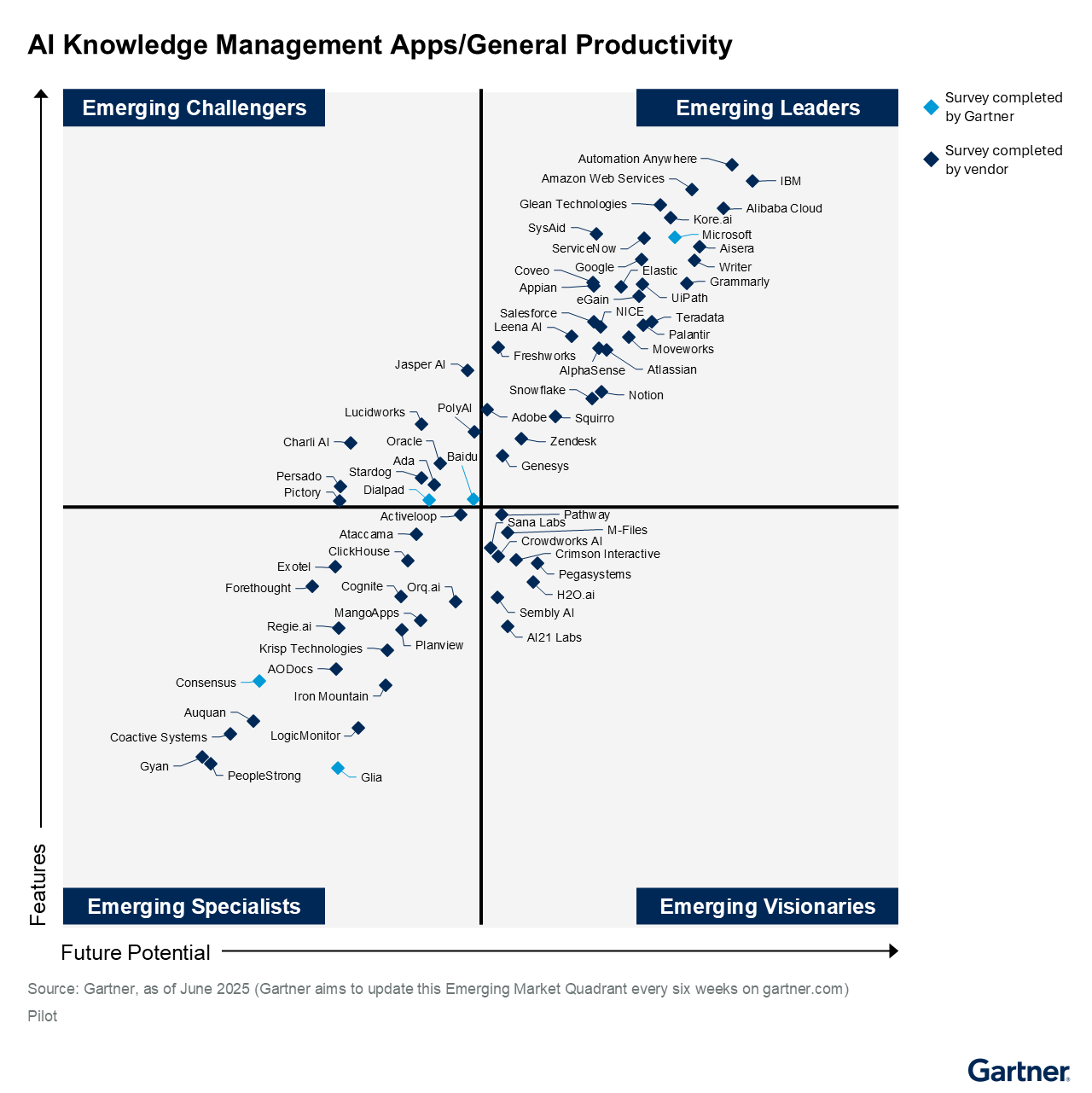
Gartner® Emerging Market QuadrantのGenAIアプリケーション部門リーダー
Gartner® eMQ for Generative AI Productivity and AI Knowledge Management Apps」レポートは、AIエージェントを使用して、コードから画像やその他のマルチモーダル出力まで、企業全体の検索、タスク自動化、コンテンツ生成によりワークフローを加速するアプリケーションを対象としている。
お客様の声
Kore.aiを活用して企業がどのようにAIの価値を提供しているかをご覧ください。
モルガン・スタンレー
「私が本当に解決しようとしていたのは、ファイナンシャル・アドバイザーに毎日15~20分の時間を返す方法でした。その余分な時間によって、彼らはより迅速に、より効果的に顧客に接触し、あるいはさらに1本の電話をかけることができます。
Shailesh Gavankar
AI戦略・実行部門責任者
AMD
「AIのグローバルリーダーとして、私たちはそのリーダーシップを私たちの職場に導入する明確な機会を見出しました。Kore.aiとの取り組みは、AIを人の代わりに使うのではなく、働き方、つながり方、リーダーシップの強化に使うことで何が可能になるかを示しています"
マーク・ジャクソン
グローバル HR テクノロジー担当ディレクター
エムファシス
「Kore.aiの戦略的導入パートナーであることを誇りに思います。Kore.aiの基盤がAWS上にあり、比類のない信頼性と拡張性を提供していることを知り、特に自信を持っています。
Nitin Rakesh
Mphasis CEO
AMD
"最も重要な瞬間には、もちろん、従業員は人とのつながりを求めています。GenAIは、人事のプロフェッショナルが従業員と関わり、より高い満足度をもたらすやりとりに立ち会うことを可能にします。"
ロバート・ガマ
SVP兼チーフ・ヒューマン・リソース・オフィサー
マイクロソフト
「Kore.aiとの戦略的パートナーシップは、企業のAIトランスフォーメーションを加速させるという我々のミッションにおける重要なマイルストーンとなります。Kore.aiの高度な会話機能とGenAI機能をマイクロソフトの堅牢なクラウドおよびAIサービスと統合することで、私たちは企業がエンタープライズグレードのセキュリティで大規模にAIを導入できるようにします。この協業により、企業は業務を合理化し、生産性を高め、主要部門全体でイノベーションを推進できるようになります。"
Puneet Chandok
マイクロソフト インド・南アジア プレジデント
AMD
「単に業務を自動化するだけでなく、よりスマートで直感的なHRエクスペリエンスを実現することが重要だと考えていました。従業員を念頭に置いて設計することで、高速で信頼性が高く、ビジネスとともに進化できるソリューションを構築しました"
レサ・セイヤー
グローバル HR シェアードサービス担当 CVP
AWS
「両社の協力関係を拡大し、AI時代における顧客のエンパワーメントという共通のコミットメントを強化できることに興奮している。
クリス・ケーシー
アジア太平洋地域および日本におけるAWSパートナーシップ責任者
オートドック
「私たちは、従業員に力を与えるためにテクノロジーを活用することに情熱を注いでいます。そのため、Kore.aiと提携し、当社のカスタマーサポートと従業員サポート業務にAIを統合しました。私たちは、74%のファーストコール解決と大幅なコスト削減を実現しています。社員はより幸せになりました。私たちは、AI for Workがもたらすシンプルさ、可能性、利点に興奮しています。"
Yuliya Teteryuk
カスタマーケアディレクター
ガイドウェル
「テクノロジーを導入するだけでなく、ヘルスケア・サポートの提供方法を進化させることです。Kore.aiによって、私たちはサイロ化されたエクスペリエンスから、モダンで拡張性があり、会員中心の真のエコシステムへと移行しました。"
Anne Hoverson
デジタル・トランスフォーメーション&ストラテジー担当副社長
インセプション
"Kore.aiとの提携は、UAEおよび世界の顧客に真のビジネス価値をもたらすAIを活用したソリューションを開発するという当社の使命と完全に一致する。"
アンドリュー・ジャクソン
CAIO、G42
ファイザー
"Kore.aiを導入して以来、研究、開発、医療、商業、製造など、グローバル市場と多言語をカバーする60のAIエージェントを企業全体に展開してきました。私たちはスケーラブルなプラットフォームを必要としており、これらのエージェントはよりインテリジェントになり続けるでしょう。"
Vik Kapoor
GenAIプラットフォーム&プロダクト部門長
ドイツ銀行
"私はドイツ銀行HRを代表し、2020年に1つの地域でささやかなFAQチャットボットから、2025年までに複数管轄地域の自動化戦略まで、私たちのAIの旅を共有する光栄に浴しています。"
ポール・ヒューイット
HR、AIイノベーション&デジタル従業員体験部門責任者
イーライリリー
「AIがTech@Lillyのサービスデスクを変革し、リクエストの70%を処理するようになった。"
マイケル・ライスト
技術部門アソシエイトディレクター
ボードウォーク・リート
「ボードウォークでは、常に居住者を第一に考えています。Kore.aiと提携することで、共感的でタイムリーなサービスを大規模に提供できるようになりました。これは単なるテクノロジーではなく、よりスマートで、よりつながりのあるコミュニティ体験の基盤なのです。"
カリーヌ・ダルコロ
カストマー・サービス部門ディレクター
戦略的パートナーマイクロソフトとAWS
私たちは世界最大のプラットフォームと連携しています。詳しくは各プラットフォームのマーケットプレイスをご覧ください。
Kore.aiのエージェントプラットフォームとビジネスソリューションは、Amazon Bedrock、Amazon Q、Amazon ConnectなどのAWSサービスと統合されており、ビジネスユースケースにおけるAWS Alツールの展開を加速します。Kore.aiはAWSマーケットプレイスでご覧いただけます。
企業は、Kore.aiのエージェントプラットフォームとビジネスソリューションを、Azure Al Foundry、Microsoft Teams、Microsoft 365 Copilot、Microsoft Copilot StudioなどのMicrosoft環境内にシームレスに導入し、Alの価値をより早く実感することができます。Kore.aiはAzure Marketplaceにあります。
AIインサイト
AI市場で何が注目されているかを学びましょう。これらのトピックは、質の高いAIエージェントを構築、展開、収益化する方法をナビゲートするのに役立つと確信しています。

ブログ - 2025年2月21日



