





Ready-to-deploy applications across industries and functions.
Leverage pre-built AI agents, templates, and integrations from the Kore.ai Marketplace.







Ai4 is a leading annual AI conference in Las Vegas where business leaders, technologists, and innovators gather to explore real-world AI applications.
.webp)
ABCs of AI: a simple approach to explaining core concepts of AI
This AI insight explains core AI concepts, including AI agents, robotic process automation (RPA), graph data, large language models (LLMS), retrieval-augmented generation (RAG), and the Agentic Spectrum, with the aim of simplifying complex terms.

Cobus Greyling
May 23, 2025
20 Min

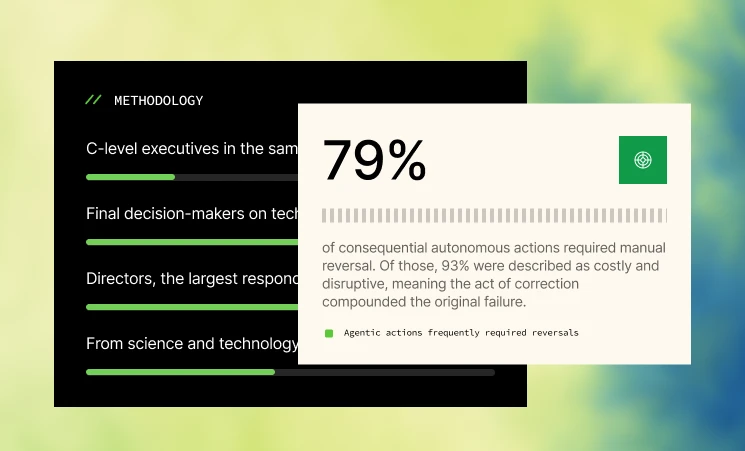
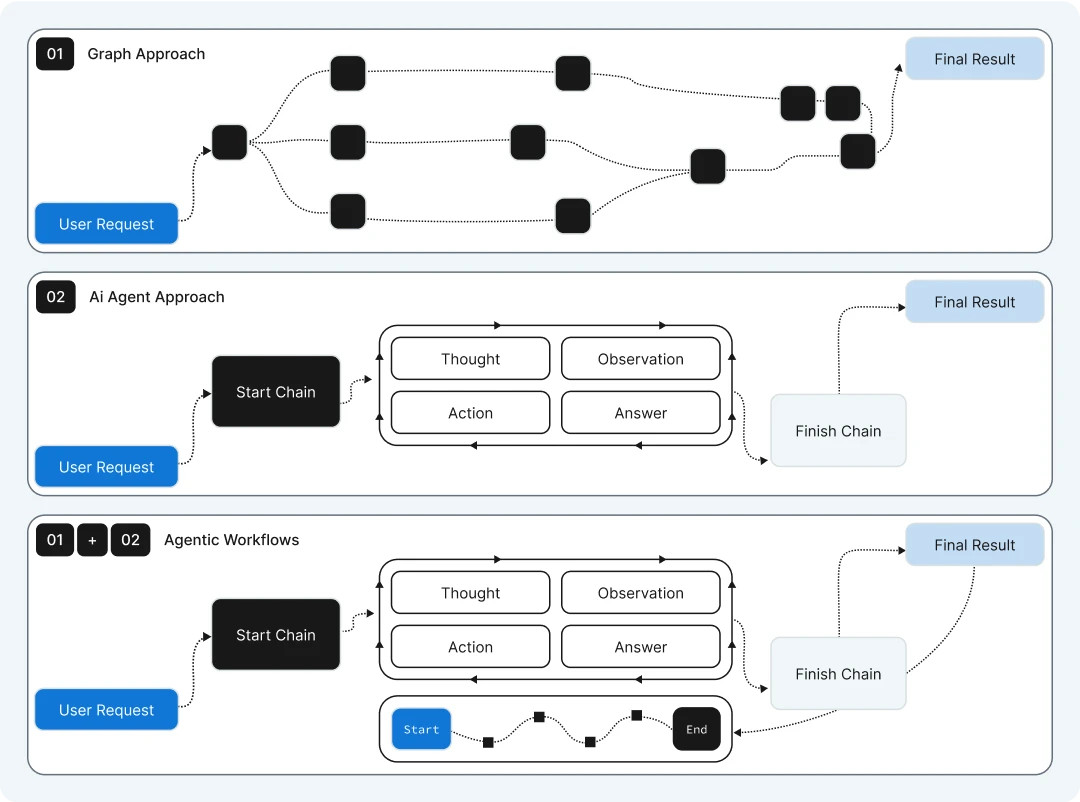
What are AI agents?
An AI Agent is a software program designed to autonomously perform tasks or make decisions based on available tools.
As illustrated below, these agents rely on one or more Large Language Models or Foundation Models to break down complex tasks into manageable sub-tasks.
These sub-tasks are organised into a sequence of actions that the agent can execute.
The agent also has access to a set of defined tools, each with a description to guide when and how to use them in sequence, addressing challenges and reaching a final conclusion.
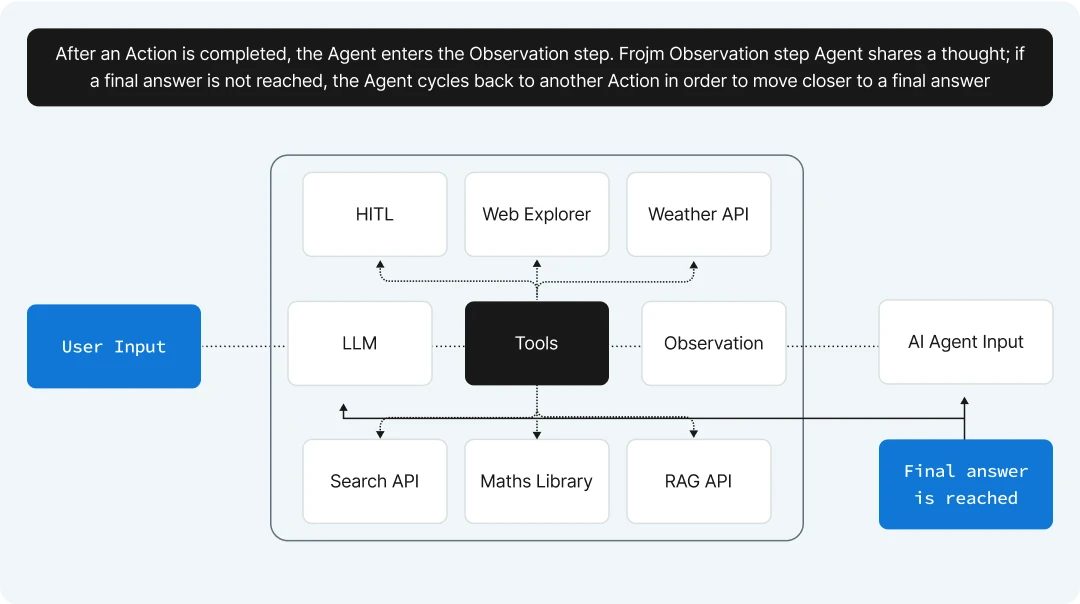
What makes them special?
When an AI agent gets a task, it starts by looking at the complex user input, like a question or problem.
It first evaluates the input to understand what’s being asked.
Then, it uses its memory to recall any useful information it already knows.
Next, the AI takes actions, which might involve breaking the task into smaller steps or trying different approaches. After each action, it observes the results to see if it’s on the right track.
Finally, the AI thinks about everything it’s learned and puts together a clear final answer.
What is RPA then?
RPA, or Robotic Process Automation, is a technology that uses software “robots” or bots to automate repetitive, rule-based tasks that humans usually do on computers.
Think of it like a digital worker that can mimic actions such as clicking, typing, or copying data between systems, but much faster and without mistakes.
For example, RPA can handle tasks like filling out forms, processing invoices, or extracting data from emails by following a set of predefined rules.
It’s great for saving time on boring, routine jobs, but it doesn’t “think” or adapt—it just follows the steps it’s programmed to do. RPA is widely used in industries like finance, healthcare, and customer service to make processes more efficient.
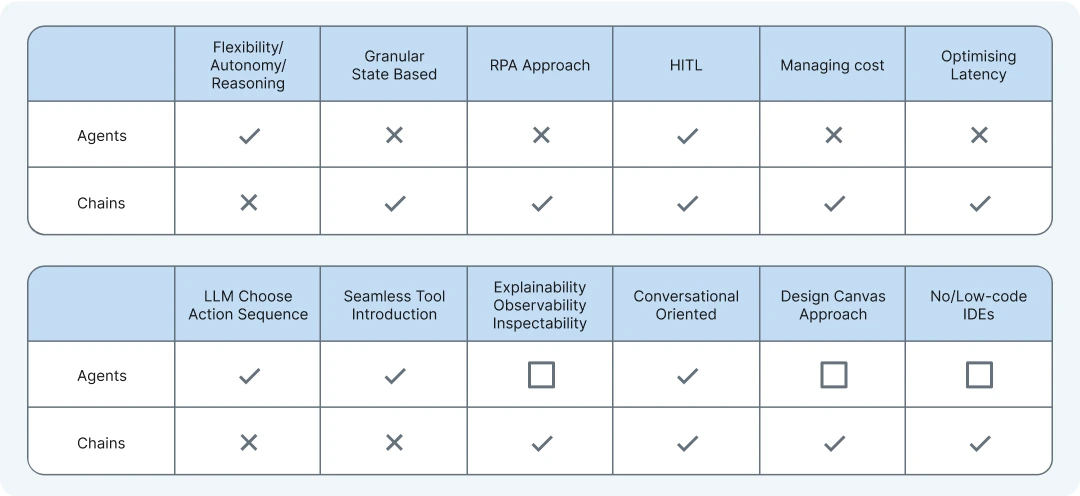
What is the difference between AI agents and RPA?
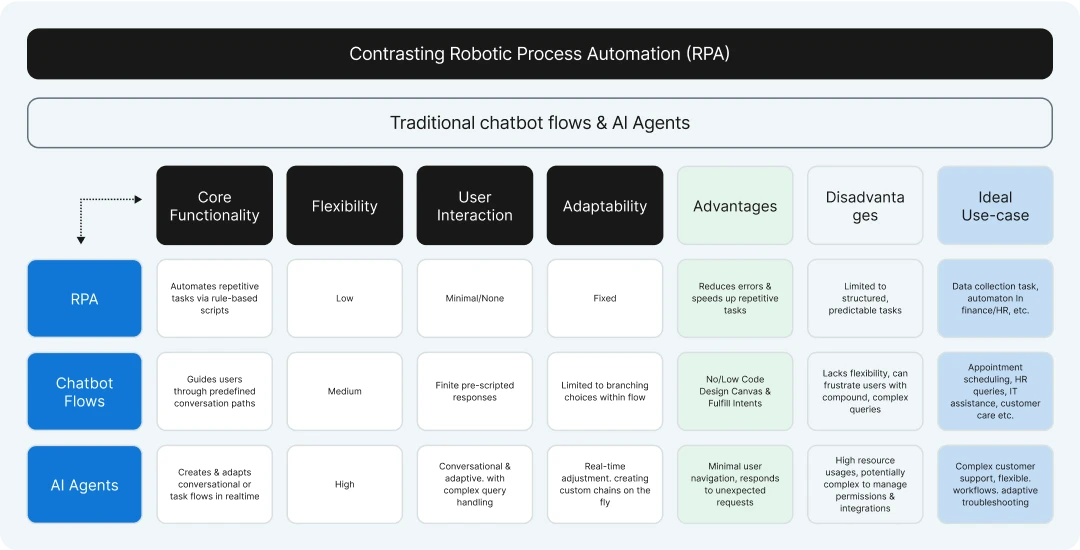
AI agents and RPA (Robotic Process Automation) flows both automate tasks, but they differ in their approach and capabilities.
AI Agents, often powered by models like LLMs, can think, learn, and adapt, handling complex tasks that require decision-making or natural language understanding.
RPA flows are rule-based systems designed to follow strict, predefined steps for repetitive tasks, like data entry or form filling.
AI Agents can interact with dynamic environments and handle unstructured data, while RPA flows work best in structured, predictable settings.
In short, AI Agents are more intelligent and flexible, while RPA flows are rigid but efficient for routine processes.
Can you explain what graph data is?
Graph data is a way to organise information using dots and lines, kind of like a map of connections.
- The dots, called nodes, represent things—like people, places, or items.
- The lines, called edges, show how those things are related, like friendships between people or roads between cities.
For example, in a social network, each person is a node, and if they’re friends, there’s an edge connecting them. It’s a simple way to show relationships and helps computers understand how things are linked together!
How does reasoning work in LLMs?
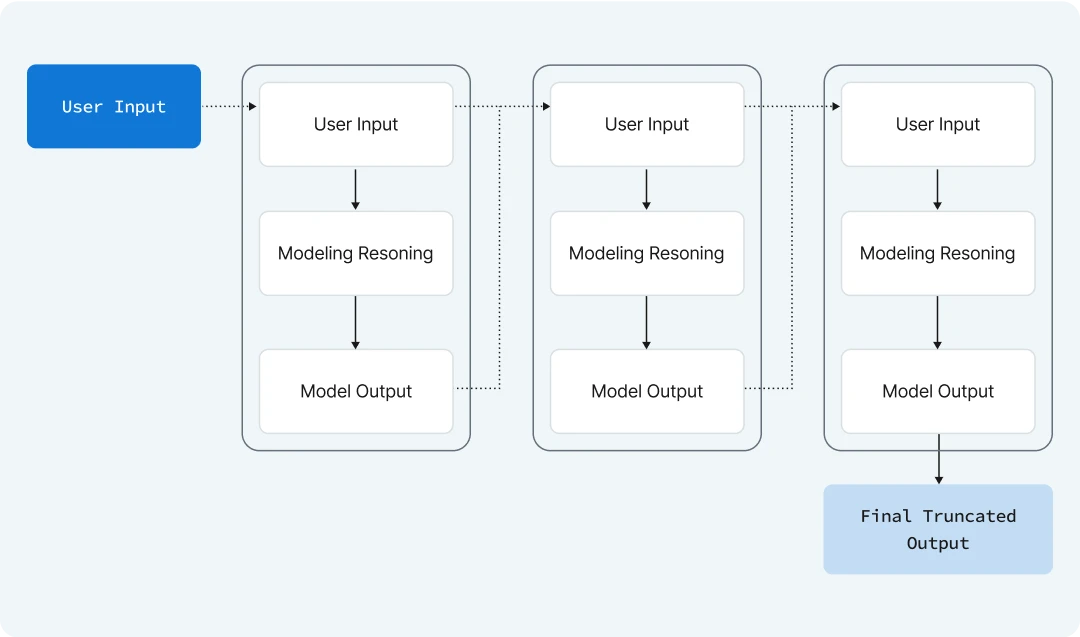
The image shows how reasoning works in Large Language Models (LLMs) in a step-by-step way.
- First, a user gives an input, like a question, to the LLM.
- The model then thinks about the input, using a process called “modeling reasoning,” to come up with an answer or idea, which is the model output.
- This process might repeat a few times, with the model refining its thoughts by going back and forth between reasoning and output.
- Finally, after a few rounds, the LLM gives a final, polished answer called the “final truncated output.”
Language model distillation demystified – part 1
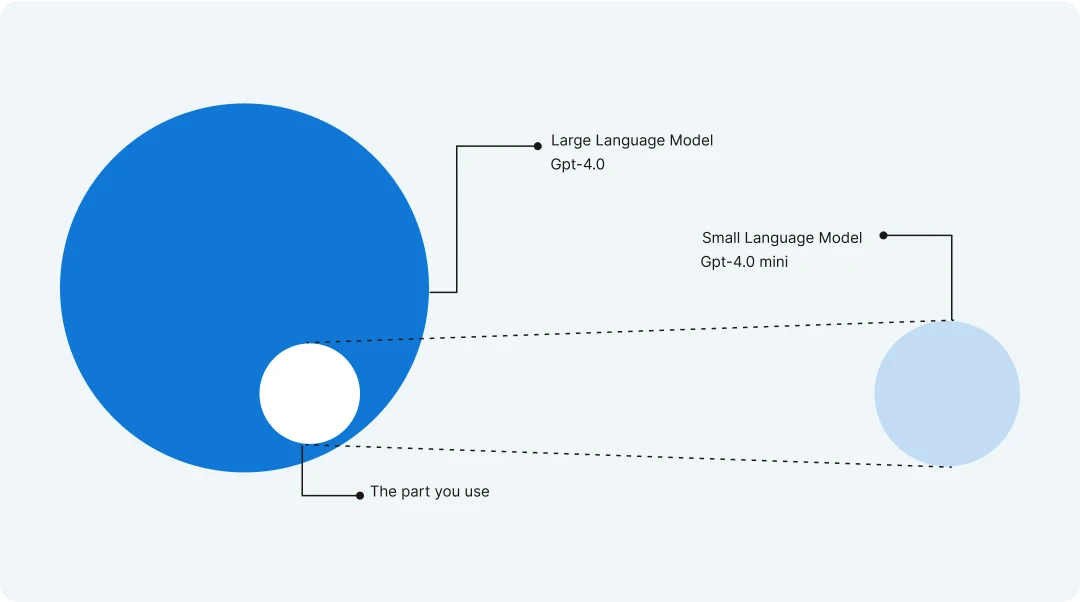
The image shows model distillation in a simple way, using circles to represent language models.
- The big green circle is a large language model, like GPT-4o, which is powerful but complex and slow.
- The smaller orange circle is a smaller model, like GPT-4o mini, which is less powerful but faster and easier to use.
Model distillation is the process of transferring knowledge from the big model to the small one, shown by the purple dotted line connecting them.
This way, the smaller model learns to act like the big one but is more efficient, making it “the part you use” for everyday tasks.
Language model distillation demystified – part 2
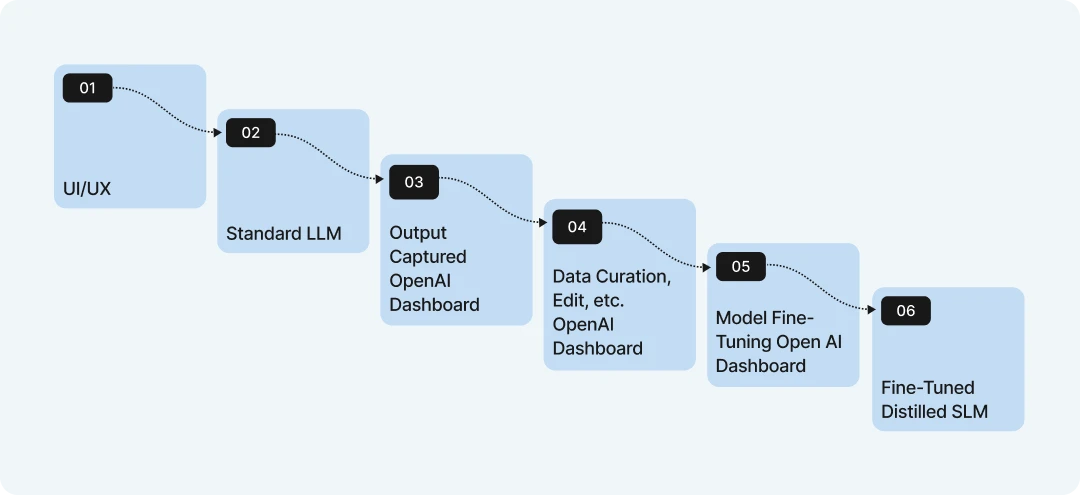
The image outlines the data process of model distillation in a clear, step-by-step way as implemented in the OpenAI environment.
- It starts with a standard Large Language Model (LLM) that takes input from a UI/UX interface, like a user’s request.
- The LLM’s responses are then captured in an “Output Captured OpenAI Dashboard,” collecting data on how the model behaves.
- Next, this data goes through “Data Curation, Edit, etc. OpenAI Dashboard,” where it’s cleaned and refined to ensure quality.
- Finally, the curated data is used in “Model Fine-Tuning OpenAI Dashboard” to train a smaller, fine-tuned model (SLM), creating a more efficient version of the original LLM.
How can RAG be explained in simple terms?

RAG, or Retrieval-Augmented Generation, is a technique that makes AI language models smarter by combining two steps:
- retrieving information and
- generating answers.
First, when you ask a question, RAG searches for relevant information from a big collection of data, like documents or a database, to find useful facts.
Then, it uses that retrieved information to help the language model create a better, more accurate answer.
Think of it like a student who looks up facts in a book before writing an essay—it helps the AI give answers that are more informed and up-to-date.
RAG is especially helpful for questions that need specific knowledge the model might not have learned during its training. It’s widely used in things like chatbots or search tools to make responses more reliable and detailed!
What is the difference between AI agents and chatbots?
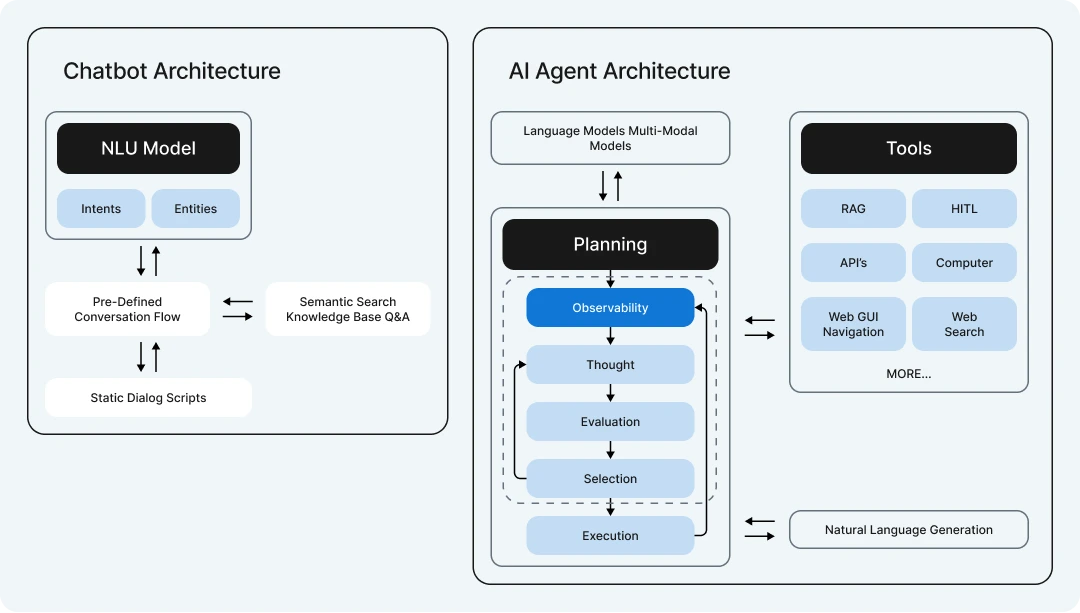
The image compares traditional chatbots and AI agents, highlighting their architectural differences.
Traditional chatbots rely on an NLU (Natural Language Understanding) model to process intents and entities, follow a pre-defined conversation flow, and use static dialog scripts or a semantic search knowledge base for Q&A, making them rigid and limited to scripted responses.
In contrast, AI Agents use advanced language and multi-modal models, integrating tools like RAG, HITL, web search, and APIs to interact with the world more dynamically.
AI Agents follow a more complex process of observation, planning, thought, evaluation, selection, and execution before generating natural language responses, allowing them to think and adapt.
Overall, chatbots are simpler and rule-based, while AI Agents are more intelligent, flexible, and capable of handling diverse tasks.
What is all this talk of the Agentic Spectrum?
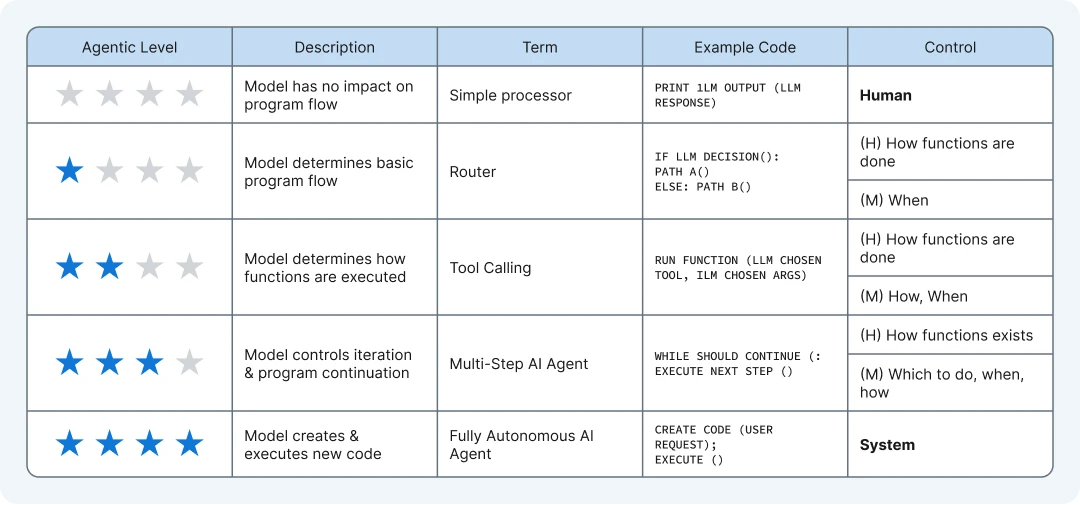
The image explains the “Agentic Spectrum,” which shows how much control and independence AI Agents have, ranging from simple to fully autonomous.
At the lowest level (1 star), a “Simple Processor” just follows basic instructions, like printing an output, with full human control.
Moving up, a “Router” (2 stars) can decide between basic paths, like choosing between two functions, with humans deciding when to act.
At 3 stars, “Tool Calling” lets the model pick and run functions, but humans still decide what functions are available and how they’re used.
Higher up, a “Multi-Step AI Agent” (4 stars) can control program flow and iterate, deciding which steps to take and when, while a “Fully Autonomous AI Agent” (5 stars) can create and execute new code independently, with the system in full control.
What if your AI could surf the web fetching exactly what you need?
Web-Navigating AI Agents: Redefining Online Interactions and Shaping the Future of Autonomous Exploration.
Agentic exploration refers to the capacity of AI agents to autonomously navigate and interact with the digital world, particularly on the web.
Web-navigating AI agents are revolutionising online interactions by automating complex tasks such as information retrieval, data analysis, and even decision-making processes.
These agents can browse websites, extract relevant data, and execute actions based on predefined objectives, transforming how users engage with online content. By reshaping the way we interact with the web, these AI agents are paving the way for more personalized, efficient, and intelligent online experiences.
As they continue to evolve, web-navigating AI agents are poised to significantly impact the future of autonomous exploration, expanding the boundaries of what AI can achieve in the digital realm.
Imagine an AI that not only reads the web but sees it like you do—clicking buttons and scanning screens with ease…

As agents grow in capability, they are also expanding into navigating by leveraging the image / visual capabilities of Language Models.
Firstly, language models with vision capabilities significantly enhance AI agents by incorporating an additional modality, enabling them to process and understand visual information alongside text.
I’ve often wondered about the most effective use-cases for multi-modal models, is applying them in agent applications that require visual input is a prime example.
Secondly, recent developments such as Apple’s Ferrit-UI, AppAgent v2 and the WebVoyager/LangChain implementation showcase how GUI elements can be mapped and defined using named bounding boxes, further advancing the integration of vision in agent-driven tasks.
What if an AI could take the wheel—how would you put it to work?
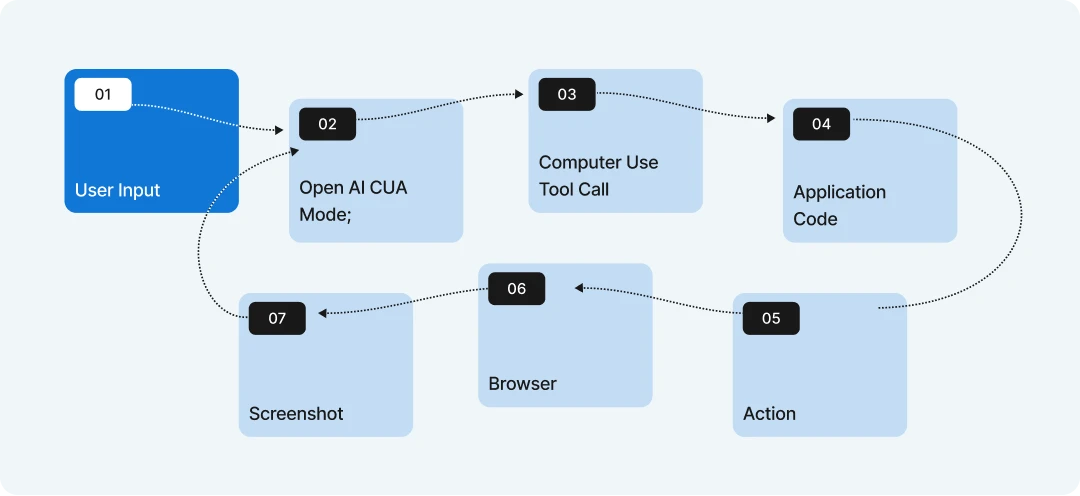
The clip shows a computer use AI Agent with a chatbot user interface. The user can ask any question which can be performed on their computer. In the example above the user asks about the best route between two cities. The Computer Use AI Agent is able to open a browser tab, navigate to Google Maps and perform a route search based on the two cities.
Another example is where the user can upload a picture of a construction site to the AI Agent, and ask to create a spreadsheet with a list of tasks. With the status and outstanding elements for each task.
Think of Computer Use AI Agents as living within the digital environment of your PC or laptop and being able to navigate between applications, building a memory and transferring information and context between different applications. Just like we do as humans.
Why is in-context learning so important for language models?
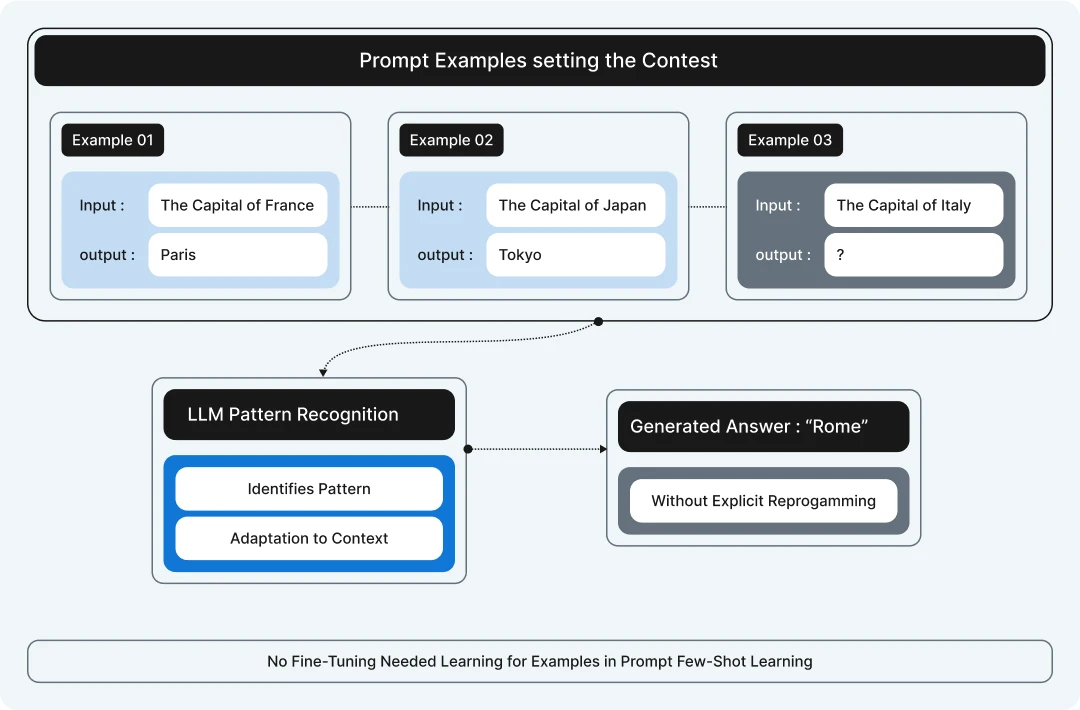
The underlying principle which enables RAG is In-Context Learning (ICL).
In-context learning refers to a large language model’s ability to adapt and generate relevant responses based on examples or information provided within the prompt itself, without requiring updates to the model’s parameters.
By including a few examples of the desired behaviour or context within the prompt, the model can infer patterns and apply them to new, similar tasks.
This approach leverages the model’s internal understanding to perform tasks like classification, translation, or text generation based solely on the context given in the prompt.
In-context learning is particularly useful for tasks where direct training on specific data isn’t feasible or where flexibility is required.
Static flow – a convenient way building simple workflows?
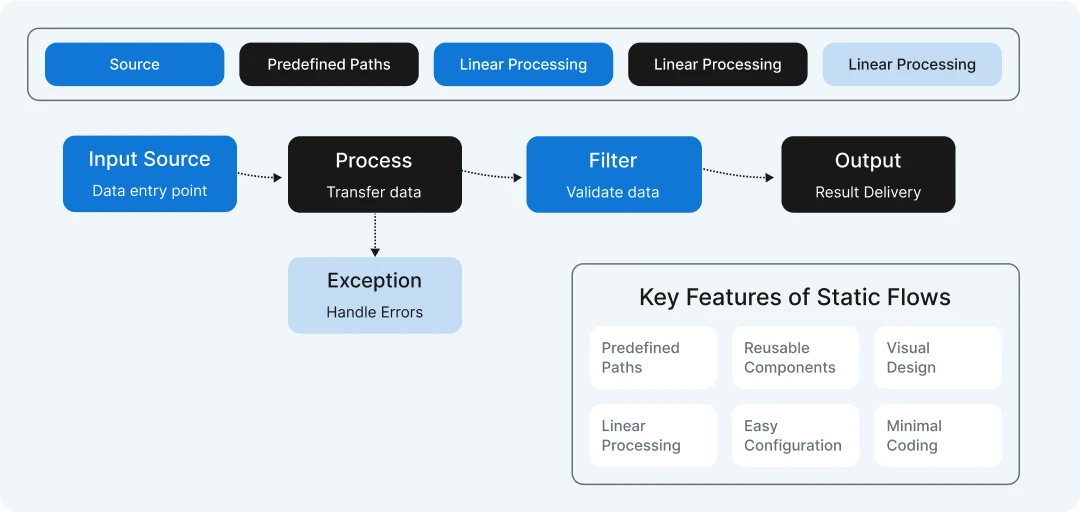
Static Flow is a user-friendly tool designed to simplify the creation of straightforward workflows.
It allows users to automate repetitive tasks by connecting apps and services with minimal coding knowledge.
With an intuitive interface, users can define triggers and actions to streamline processes like data transfer or notifications.
Static Flow supports integration with popular platforms, making it versatile for small businesses and individuals. Its drag-and-drop functionality ensures quick setup and efficient management of simple automation tasks.
What is prompt chaining then?
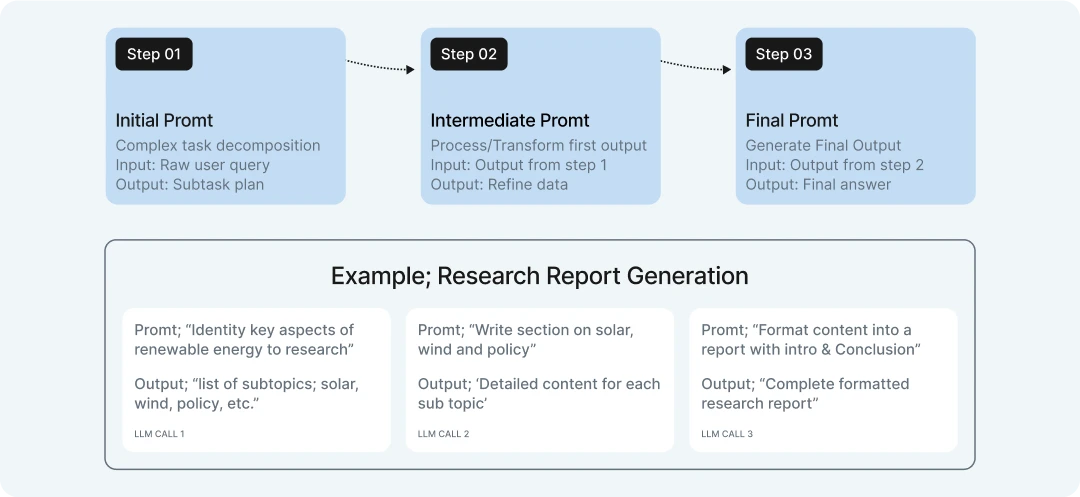
Prompt chaining is a powerful technique that breaks down complex tasks into a sequence of smaller, more manageable prompts, where the output of one step becomes the input for the next. This approach allows LLMs to tackle problems that would be too complex to handle in a single prompt.
Key components in the diagram:
- Sequential Processing Flow:
- Step 1: Initial Prompt – Takes the raw user query and breaks it down into manageable subtasks
- Step 2: Intermediate Prompt – Processes the results from the first step, transforming or refining the data
- Step 3: Final Prompt – Generates the final output based on processed information
- Example Workflow: Research Report Generation:
- Topic Analysis – First LLM call identifies key subtopics to research
- Content Generation – Second LLM call creates detailed content for each subtopic
- Final Formatting – Third LLM call assembles everything into a cohesive, formatted report
- Benefits:
- Overcomes token context limitations by splitting work across multiple prompts
- Creates checkpoints where humans can verify intermediate results
- Allows each step to specialize in a specific subtask
- Enables more controlled reasoning for complex problems
Prompt chaining is particularly useful for tasks that require multiple stages of processing, research, or when the final output needs to incorporate insights from different analytical steps.
What is Prompt Engineering?
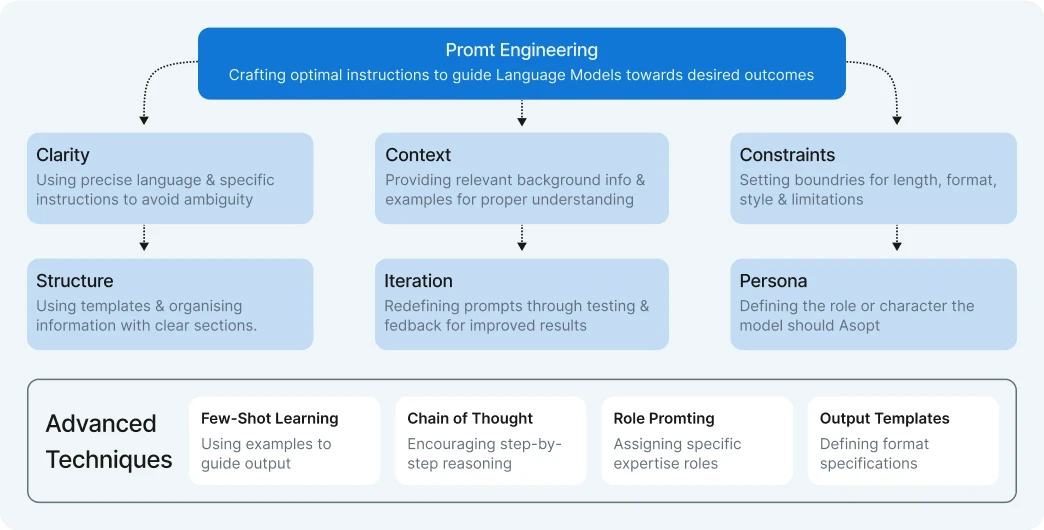
The diagram illustrates the multifaceted nature of prompt engineering – the art and science of crafting optimal instructions to get the best results from large language models.
Core components
At the center is the fundamental concept of Prompt Engineering, surrounded by six key principles:
- Clarity: Using precise language and specific instructions to minimize ambiguity and misinterpretation. Clear prompts lead to clear outputs.
- Context: Providing background information, details, and examples that help the model understand the full scope of what’s needed.
- Constraints: Setting appropriate boundaries for length, format, style, and other parameters to guide the model toward the desired output characteristics.
- Structure: Organizing prompts with logical flow and clear sections, often using templates or consistent formatting to improve model comprehension.
- Iteration: Refining prompts through testing and feedback cycles to progressively improve results and address shortcomings.
- Persona: Defining specific roles or characters for the model to adopt, which can significantly influence tone, expertise level, and perspective.
Advanced techniques
The bottom section highlights specialized prompt engineering approaches:
- Few-shot learning: Including examples within the prompt to demonstrate the desired pattern or format
- Chain-of-thought: Prompting the model to work through problems step-by-step for improved reasoning
- Role prompting: Assigning specific expertise roles to align responses with particular knowledge domains
- Output templates: Specifying exact output formats to ensure consistent, usable results
Effective prompt engineering is iterative and context-dependent – what works best varies based on the specific task, model, and desired outcome. The most successful approaches often combine multiple principles and techniques to create prompts that reliably produce high-quality results.
What is the first step to make prompts flexible?
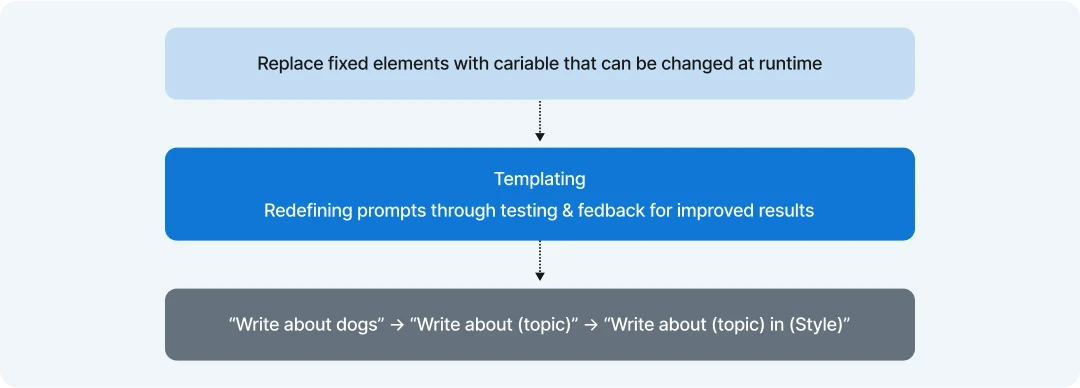
The diagram illustrates that parameterization is the critical first step in creating flexible prompts for language models. This foundational concept involves replacing fixed elements in your prompts with variables that can be changed at runtime.
How parameterization works:
- Identify fixed elements: Examine your prompt for specific values, topics, or instructions that might need to change depending on the situation.
- Replace with variables: Convert these fixed elements into parameters that can be dynamically filled in.
- Create a template: Develop a reusable pattern with clearly marked placeholders for the variable content.
- Test across use cases: Verify that your parameterized prompt works effectively with different variable values.
Example transformation:
- Original (rigid): “Write about dogs”
- Parameterized (single variable): “Write about {topic}”
- Advanced (multiple variables): “Write about {topic} in {style}”
Key benefits:
- Reusability: The same prompt template can be used repeatedly with different inputs
- Adaptability: Prompts can be easily modified for various scenarios without rewriting
- Scalability: One well-designed prompt can serve many use case
By starting with parameterization, you create a foundation for more sophisticated prompt engineering techniques like conditional logic, dynamic formatting, and context-aware variations.